We Taught Robots to Make Movies and Now We’re All Doomed (In a Fun Way)
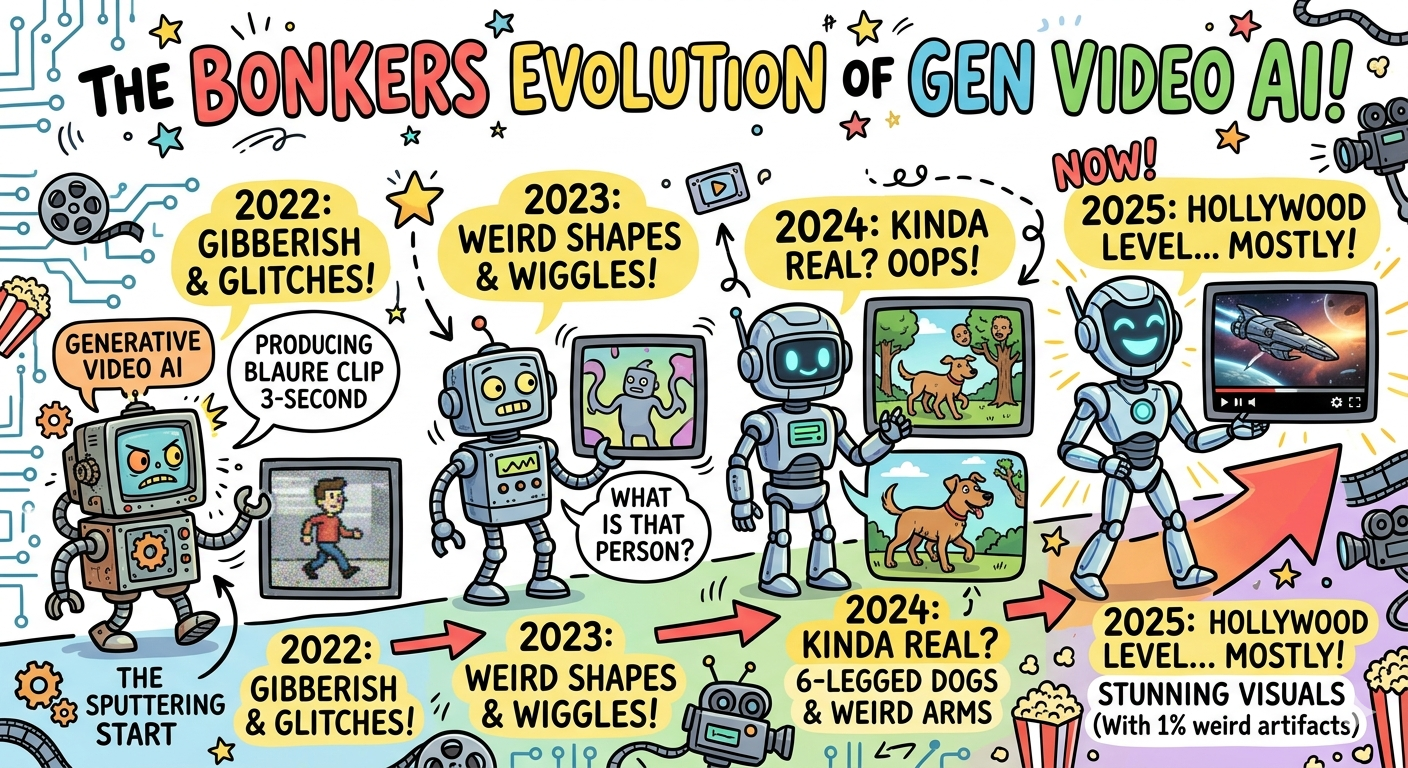
A brief, chaotic history of AI video generation — from cursed pixel soup to “wait, is that real?”
—–
Picture this: it’s 2016. Somewhere in a research lab, a very serious group of very serious scientists gather around a monitor to watch their AI’s first attempt at generating a video of a person walking.
The result? A sentient blob of beige pixels having what can only be described as an existential crisis. Limbs in places limbs should not be. A face that looked like someone described a human to a very tired alien. Motion that suggested the subject was simultaneously walking, melting, and auditioning for a horror film.
The scientists cheered anyway. Because buried inside that beautiful disaster was the seed of something that would, in less than a decade, completely lose its mind and change the world.
Buckle up.
—–
Chapter One: GANs — The “Two AIs Walk Into a Bar” Era
Before we get to the good stuff, we need to talk about GANs — Generative Adversarial Networks. The concept, introduced by Ian Goodfellow in 2014, is genuinely one of the most unhinged ideas in computer science history, and I mean that as a compliment.
The setup: you take two neural networks and make them fight each other. One (the Generator) tries to create fake content. The other (the Discriminator) tries to catch it lying. They go back and forth, millions of times, until the Generator gets so good at lying that even the Discriminator gets fooled. It’s essentially training an AI by teaching it to gaslight another AI.
For still images, GANs were incredible. For video? Complete chaos.
Here’s the thing nobody tells you about video: it’s not just pictures. Video is pictures that have to *make sense over time*. Physics has to apply. If you throw a ball, it has to arc properly. If someone blinks, they can’t un-blink two frames later. A cup of coffee cannot spontaneously teleport across the table between shots — unless you’re making a very experimental art film.
Early video GANs simply did not care about any of this. Objects flickered in and out of existence. Backgrounds pulsed like living organisms. Human faces went through stages of evolution mid-clip. The results were technically video in the same way that a fever is technically a warm bath — yes, heat is involved, but something has gone very wrong.
Researchers kept at it though, because that’s what researchers do. They are, as a species, pathologically optimistic.
—–
Chapter Two: Diffusion Models Arrive and Fix Everything (Sort Of)
Around 2020, a different approach started quietly stealing the spotlight: diffusion models. The idea sounds almost meditative. Take an image. Slowly destroy it by adding random noise until it’s pure static. Then train a neural network to reverse that process — to reconstruct order from chaos, signal from noise.
When this approach finally exploded with DALL-E and Stable Diffusion for images, everyone immediately wondered: *can we do this for video?*
Spoiler: yes. And it was a revelation.
Diffusion models turned out to be naturally good at the thing GANs were terrible at — keeping things consistent. Because they work by gradually refining and smoothing, they apply that same smoothing logic across frames. Less flickering. Less spontaneous face-melting. Fewer cups of coffee teleporting across tables.
By 2023, Runway ML, Stability AI, and others were putting text-to-video tools directly into users’ hands. You typed “a golden retriever surfing at sunset” and received — not perfectly, not without the occasional extra leg — but genuinely, recognizably, *a golden retriever surfing at sunset*.
The creative community collectively lost their minds. In a good way. Mostly.
—–
Chapter Three: Sora Shows Up and Everyone Needs a Moment
February 2024. OpenAI drops Sora demos on an unsuspecting internet and causes what can only be described as a collective reality check for the entire planet.
We’re talking long videos. Multiple camera angles. Characters that stayed consistent across scenes. Physics that actually behaved like physics. A video of a Tokyo street at night that people genuinely could not immediately identify as AI-generated.
But here’s the truly wild part — OpenAI didn’t just say “look at our cool video tool.” They said: *this model might be learning how the world actually works.*
Think about that. To predict what the next frame of a video looks like, you have to understand that fire is hot, water flows downhill, and if you drop a glass it shatters rather than bouncing gently into someone’s hand. Sora, they argued, was not just generating video — it was building something like a physics engine out of sheer pattern recognition. A *world simulator*.
At which point everyone in AI research took a very long walk outside and stared at the sky for a while.
—–
Chapter Four: The Absolute Chaos That Followed
After Sora, the floodgates opened and the industry absolutely sprinted.
Google DeepMind shipped Veo. China’s Kuaishou released Kling and it was *startlingly* good. Luma AI’s Dream Machine let anyone generate cinema-quality clips from their phone. Adobe quietly integrated video generation into Premiere Pro, and the sound you heard was a million video editors having complicated feelings.
Ad agencies started generating full campaigns in hours. Independent filmmakers started making shorts with production values that would have cost millions a few years prior. A teenager with a laptop and a good prompt could create visual content that once required an entire crew.
The barrier to visual storytelling — historically guarded by expensive cameras, specialized talent, and the kind of budget that comes with having a studio behind you — started dissolving at an almost uncomfortable speed.
—–
So Where Are We Heading?
Longer videos with consistent storylines. Characters you can lock in and carry across an entire film. Interactive worlds that respond to you in real time. And if the world model hypothesis pans out — AI that genuinely understands physical reality well enough to help design drugs, train robots, and simulate universes.
Not bad for a technology that started as a haunted beige blob trying to walk.
The robots learned to dream in 2016. Then they learned to dream *well*. Now they’re learning to dream *long and consistently*, which, honestly, is more than I can say for myself most nights.
The future of video is being written one generated frame at a time. And for once, I cannot wait to see how the movie ends.
—–
*Now go outside. Touch some grass. And appreciate that the sunset you’re watching is (probably) still real.*


